科技| AI颈带读取喉部肌肉动作 不发声也可用“自己声音”说话
[星岛综合报道]南韩浦项科技大学(POSTECH)研究团队开发一款柔软矽胶颈带,结合微型镜头、动作感应器及人工智能模型,可读取佩戴者无声读字时颈部皮肤与肌肉的细微变化,再将内容转化为语音,并以接近用户本人的声线播放。
这款装置针对“无声语音介面”而设计。研究指出,人类说话时即使没有发声,口腔、喉咙及颈部皮肤仍会出现可预测的变形。过往相关技术多依赖肌电图或脑电图,但通常需要笨重设备及贴附式电极,舒适度及实际应用都有限。
POSTECH 的方案改用软身矽胶颈带,内置“多轴应变映射感测器”,不但侦测皮肤变形幅度,亦能辨识移动方向。颈带上的参考标记配合微型镜头,可即时量度颈部变化;演算法则会修正每次佩戴位置的细微差异,令系统读取更稳定。
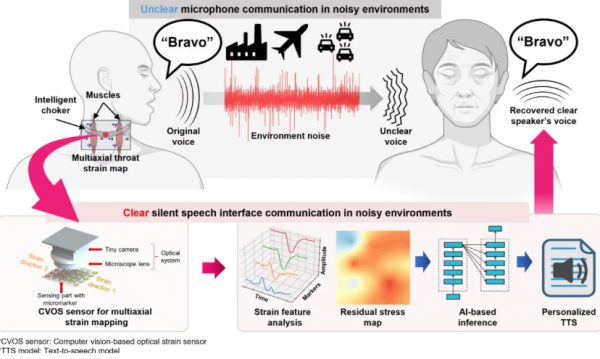
测试中,系统以北约音标字母表的 26 个字词作训练,例如 Alpha、Bravo、Charlie 等,辨识准确率达 85.8%。当 AI 辨认出用户无声读出的字词后,会无线传送至伺服器,再由个人化文字转语音模型合成声音。研究人员称,只需少于 10 分钟录音,系统便可模拟用户的语调及声音特征。
研究亦显示,装置在约 90 分贝白噪音环境下仍可维持最高 33.75 分贝讯噪比,表现较商用肌电系统佳。团队认为,技术有望协助喉切除患者、语言障碍人士,也可用于工业、救援、航空、航海及军事等高噪音环境。
不过,现阶段技术仍有明显限制。系统只能辨识 26 个预设字词,未能支援自由对话;若佩戴者步行或大幅摆动头部,准确率可跌至 39.72%。研究团队下一步将扩大测试人数、增加词汇量,并改善身体活动时的稳定性。
相比英国剑桥大学早前同类颈带研究曾录得 95.25% 解码准确率,POSTECH 方案的特点在于加入个人化 AI 声音重建,令无声沟通不只是“读出文字”,而是更接近以本人声音重新说话。
图片:POSTECH
T10